There is a concept that is starting to take shape in the hospitality industry: the language tax—a “silent tax” you pay every time you interact with an LLM (a large language model capable of understanding and generating human language at scale) in a language other than English. And we’re not talking about something theoretical or marginal. We’re talking about a real, measurable cost that adds up month after month for teams that have already integrated AI into their daily operations.
Large language models—GPT, Claude, Gemini, Llama—process text through tokenizers. These tokenizers break words into smaller units before processing them. The problem is that they were trained predominantly on English text, which makes them significantly more efficient in that language. When you write in Spanish, French, or German, the model needs more tokens to process exactly the same content. More tokens = higher cost.
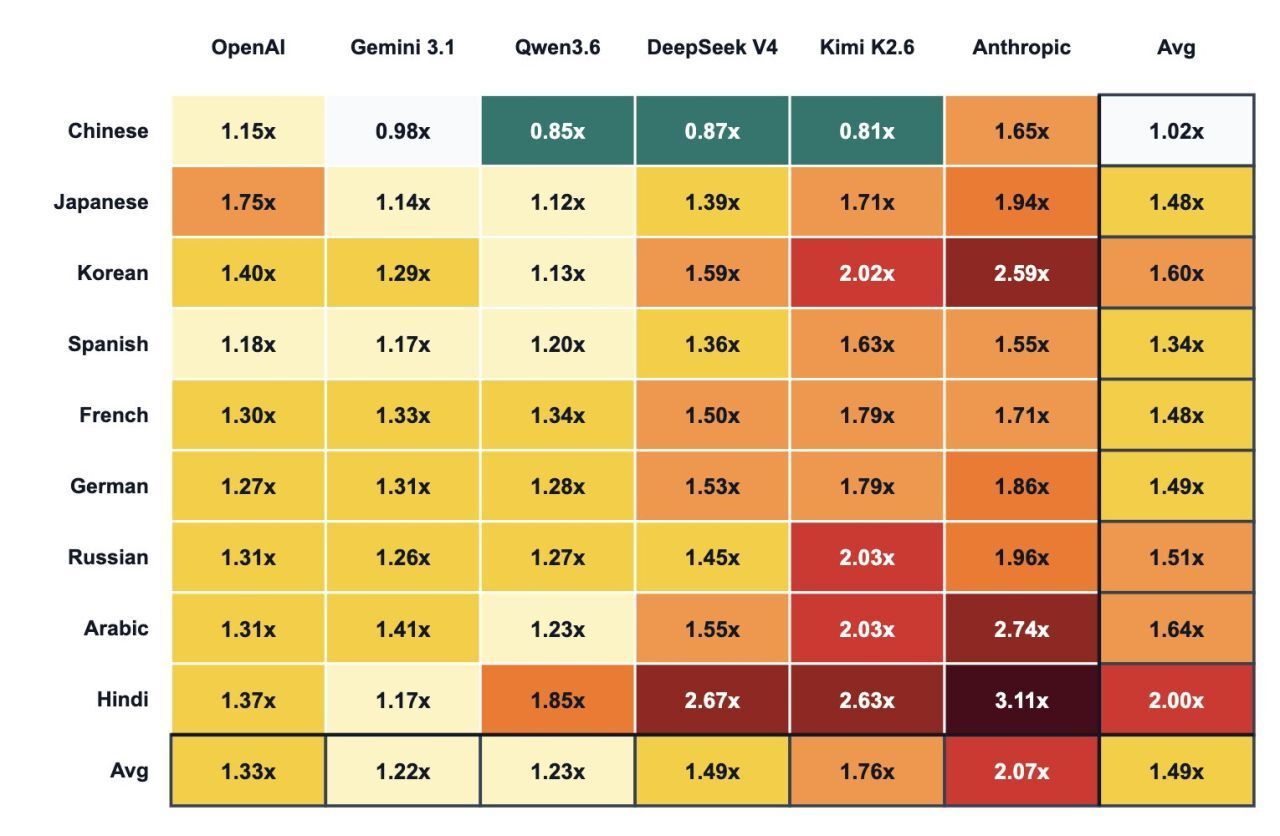
Claude’s case: the highest multiplier on the market
Among all the providers analyzed, the one with the worst linguistic efficiency ratio is Anthropic with its Claude model, which shows an average multiplier of 2.07× for Spanish compared to English. Put into practical terms: if you write to Claude in Spanish, you are paying—on average—more than twice as many tokens as you would if you wrote exactly the same thing in English.
For a team that uses Claude only occasionally, the impact is negligible. But for a revenue management or marketing department that works with AI on a daily basis—interpreting pick‑up reports, generating responses to reviews, automating communications with OTAs, or analyzing demand data—that multiplier turns into a budget line item that no one approved and very few have even noticed.
If it’s a 100% Spanish‑language project, should I write the prompts in English?
The short answer is: it depends on what you’re optimizing for. If the project is in Spanish—the team works in Spanish, the documents are in Spanish, and the final output is in Spanish—switching to English just to save tokens introduces real friction: a higher risk of translation errors, lost context, and extra review cycles. That operational cost can easily outweigh the token savings.
The language tax becomes truly relevant mainly when usage volume is very high and English is a viable working language. For most hotel teams in Spain, it isn’t. What is worth doing is understanding that cost before making a decision—not necessarily switching to English. The practical takeaway isn’t “write to the AI in English,” but rather “choose the provider and model deliberately, knowing what each one costs you in your own language.”

What does all of this mean for the hospitality sector, and why is it critical?
Revenue and marketing teams have been early adopters of technology in hotels for years. Revenue teams were the first to integrate RMS solutions, the first to connect PMS platforms with dynamic pricing tools, and are now among the first to incorporate generative AI workflows. Meanwhile, marketing and e‑commerce departments were the first to bring social media into hotel strategy, to build and manage websites with CMS platforms, to work with campaign automation and audience segmentation tools, and they now lead the personalization of the guest’s digital experience even before the guest reaches the front desk.
But in this wave of adoption, there is one variable that is rarely analyzed: the language used to talk to the machine. A revenue manager in Spain who every morning asks Claude to interpret the demand report, suggest rate adjustments, draft a response to a negative Booking review, and generate an executive summary for the management committee is consuming tokens at a much higher rate than an English‑speaking counterpart doing exactly the same work. And this has a cost which, if high enough, could end up limiting the use of the tool due to unexpected budget growth.
A concrete scenario: imagine a revenue team that carries out 50 AI interactions per day. If each interaction in Spanish consumes, on average, 300 more tokens than in English, that’s an extra 15,000 tokens per day. Over a month, 450,000 additional tokens. Over a year, more than 5 million tokens that simply wouldn’t exist if the same work were done in English. At current pricing from major providers, that volume can represent hundreds or even thousands of euros per year. A cost that doesn’t appear in any P&L report, but that very much exists—and can be hard to justify to an executive team that isn’t particularly friendly toward the latest technologies on the market.
The good news
The gap is narrowing, and next‑generation models are showing clear improvements in multilingual efficiency, with some providers making linguistic parity an explicit technical priority. On top of that, there are practical strategies that can minimize the impact today: writing prompts in English when the final output can also be in English, using bilingual templates for the most recurring interactions, evaluating which provider offers the best efficiency ratio for the language your team works in, and—above all—measuring. Very few teams have real visibility into token consumption per task. Gaining that visibility is the first step toward optimization.
In Revenue Management, we are used to optimizing every variable: rate, channel, segment, timing. But we rarely examine the cost of tools with the same level of scrutiny we apply to customer acquisition costs. The language tax is a reminder that AI is not neutral, and that every implementation decision— which model, in which language, for which task—comes with an associated cost. Knowing that cost is part of the job, because in revenue, every euro counts, including the ones spent on tokens.