Hi ha un concepte que comença a prendre forma en la indústria hotelera: el language tax — un «impost silenciós» que es paga cada vegada que s’interactua amb un LLM (un gran model de llenguatge capaç d’entendre i generar llenguatge humà a gran escala) en una llengua que no és l’anglès. I no es tracta d’una idea teòrica ni anecdòtica. És un cost real i mesurable, que s’acumula mes rere mes per als equips que ja han integrat la IA en les seves operacions quotidianes.
Els grans models de llenguatge — GPT, Claude, Gemini, Llama — processen el text mitjançant tokenitzadors. Aquests tokenitzadors fragmenten les paraules en unitats més petites abans del processament. El problema és que s’han entrenat majoritàriament amb textos en anglès, cosa que els fa clarament més eficients en aquesta llengua. Quan s’escriu en castellà, en francès o en alemany, el model necessita més tokens per processar exactament el mateix contingut. Més tokens equivalen a un cost més elevat.
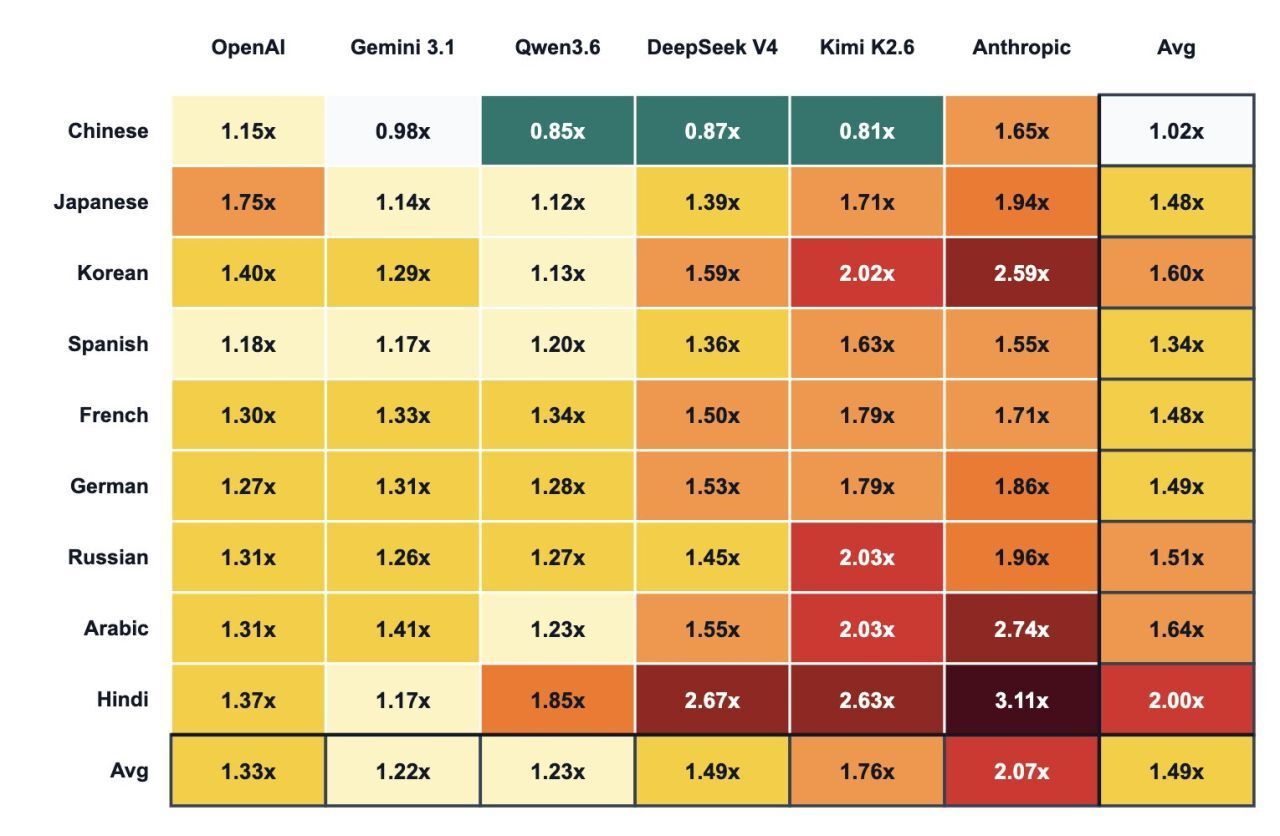
El cas de Claude: el multiplicador més alt del sector
D’entre tots els proveïdors analitzats, el que presenta el pitjor ràtio d’eficiència lingüística és Anthropic amb el seu model Claude, amb un multiplicador mitjà de 2,07x per al castellà en comparació amb l’anglès. Traduït a la pràctica: si escrius a Claude en castellà, estàs pagant —de mitjana— més del doble en tokens que si li adrecis exactament el mateix contingut en anglès.
Per a un equip que utilitza Claude de manera ocasional, l’impacte és irrellevant. Però per a un departament de revenue management o de màrqueting que treballa diàriament amb IA —interpretant informes de pick-up, generant respostes a ressenyes, automatitzant comunicacions amb les OTA o analitzant dades de demanda—, aquest multiplicador es converteix en una partida de cost que ningú ha aprovat en pressupost i que molt pocs han detectat.
Si és un projecte 100% en castellà, he de treballar les comandes en anglès?
La resposta curta és: depèn de què estiguis optimitzant. Si el projecte és en llengua castellana —l’equip treballa en castellà, la documentació és en castellà i el resultat final és en castellà—, canviar a l’anglès per estalviar tokens introdueix friccions reals: més risc d’errors de traducció, pèrdua de context i revisions addicionals. Aquest cost operatiu pot superar perfectament l’estalvi en tokens.
El language tax és un cost rellevant principalment quan el volum d’ús és molt elevat i l’anglès és viable com a llengua de treball. Per a la majoria d’equips hotelers a Espanya, no ho és. El que realment val la pena és conèixer aquest cost abans de decidir, no necessàriament canviar a l’anglès. La conclusió pràctica no és “escriu-li en anglès”, sinó “tria el proveïdor i el model amb criteri, sabent quant et costa cada un en la teva llengua”.

Què significa tot això per al sector hoteler, i per què és crucial?
Els equips de revenue i de màrqueting han estat durant anys els early adopters de la tecnologia dins del sector hoteler. Els equips de revenue van ser els primers a integrar solucions de RMS, els primers a connectar els PMS amb eines de tarifació dinàmica, i avui es troben entre els primers a incorporar fluxos de treball basats en IA generativa. Per la seva banda, els departaments de màrqueting i e‑commerce van ser els primers a integrar les xarxes socials en l’estratègia hotelera, a crear i gestionar webs mitjançant CMS, a treballar amb eines d’automatització de campanyes i de segmentació d’audiències, i actualment lideren la personalització de l’experiència digital del client, fins i tot abans que arribi a recepció.
Però en aquesta onada d’adopció, hi ha una variable que gairebé mai no s’analitza: la llengua amb què ens adrecem a la màquina. Un revenue manager a Espanya que cada matí demana a Claude que interpreti l’informe de demanda, que proposi ajustos tarifaris, que redacti una resposta a una ressenya negativa a Booking i que generi un resum executiu per al comitè de direcció consumeix tokens a un ritme molt superior al del seu homòleg anglòfon que fa exactament la mateixa feina. I això té un cost que, si esdevé massa elevat, pot acabar limitant l’ús de l’eina a causa d’un increment pressupostari inesperat.
Un escenari concret: imaginem un equip de revenue que fa 50 interaccions diàries amb una IA. Si cada interacció en castellà consumeix, de mitjana, 300 tokens més que en anglès, això representa 15.000 tokens addicionals al dia. En un mes, 450.000 tokens extres. En un any, més de 5 milions de tokens que no existirien si la mateixa feina es fes en anglès. Als preus actuals dels principals proveïdors, aquest volum pot suposar centenars, fins i tot milers d’euros l’any. Un cost que no apareix en cap compte de resultats (P&L), però que existeix —i que pot ser difícil de justificar davant d’una direcció poc receptiva a les tecnologies més recents del mercat.
La bona notícia
La bretxa es redueix, i els models de nova generació mostren millores clares en l’eficiència multilingüe. Alguns proveïdors fins i tot han convertit la paritat lingüística en una prioritat tècnica explícita. A més, ja existeixen estratègies concretes per limitar-ne l’impacte: redactar els prompts en anglès quan el lliurable final també pot ser-ho, utilitzar models bilingües per a les interaccions més recurrents, avaluar quin proveïdor ofereix el millor ràtio d’eficiència per a la llengua de treball del teu equip i —sobretot— mesurar. Molt pocs equips disposen d’una visibilitat real sobre el consum de tokens per tasca. Aconseguir-la és el primer pas cap a l’optimització.
En Revenue Management, estem acostumats a optimitzar cada variable: el preu, el canal, el segment, el timing. Però poques vegades analitzem el cost de les eines amb el mateix nivell de detall que el cost d’adquisició del client. El language tax és un recordatori que la IA no és neutral i que cada decisió d’implementació —quin model, en quina llengua, per a quina tasca— té un cost associat. Conèixer aquest cost forma part de l’ofici, perquè en revenue cada euro compta, inclosos els que es gasten en tokens.