Hay un concepto que empieza a coger forma en la industria hotelera: el language tax, un “impuesto silencioso” que pagas cada vez que interactúas con un LLM (modelo de inteligencia artificial capaz de entender y generar lenguaje humano a gran escala) en un idioma distinto al inglés. Y no estamos hablando de algo teórico o marginal. Estamos hablando de un coste real, medible, que se acumula mes a mes en los equipos que ya han integrado la IA en su operativa diaria.
Los grandes modelos de lenguaje —GPT, Claude, Gemini, Llama— procesan el texto a través de tokenizadores. Estos tokenizadores fragmentan las palabras en unidades más pequeñas antes de procesarlas. El problema es que fueron entrenados mayoritariamente con texto en inglés, lo que los hace significativamente más eficientes con ese idioma. Cuando escribes en español, en francés o en alemán, el modelo necesita más tokens para procesar exactamente el mismo contenido. Más tokens = más coste.
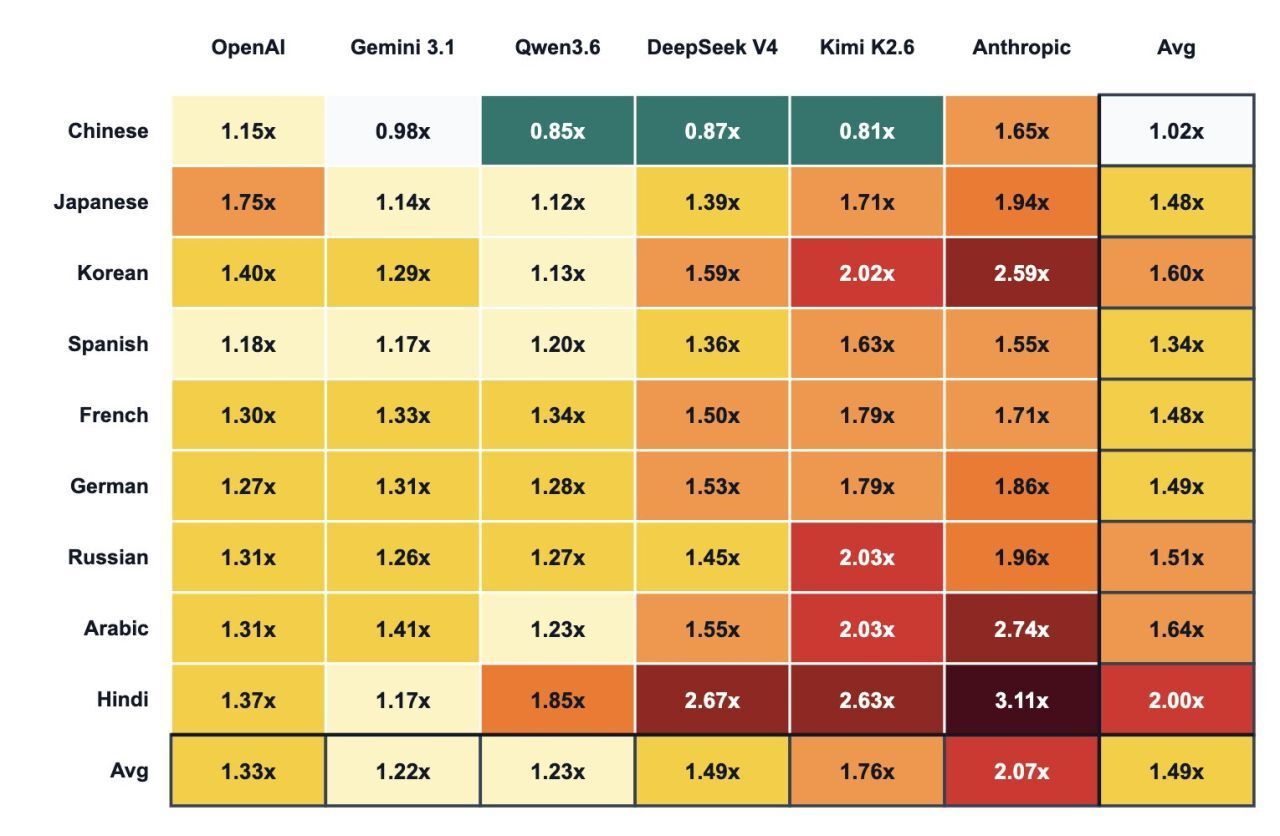
El caso de Claude: el multiplicador más alto del mercado
De entre todos los proveedores analizados, el que presenta el peor ratio de eficiencia lingüística es Anthropic con su modelo Claude, con un multiplicador promedio de 2.07x para el español frente al inglés. Traducido a la práctica: si le escribes a Claude en español, estás pagando —de media— más del doble en tokens que si le escribieras exactamente lo mismo en inglés.
Para un equipo que usa Claude ocasionalmente, el impacto es irrelevante. Pero para un departamento de revenue management o marketing que trabaja a diario con IA —interpretando pick-up reports, generando respuestas a reseñas, automatizando comunicaciones con OTAs o analizando datos de demanda—, ese multiplicador se convierte en una línea de coste que nadie ha aprobado en presupuesto y que muy pocos han detectado.
¿Si es un proyecto 100% en idioma español, trabajo los comandos en inglés?
La respuesta corta es: depende de qué estás optimizando. Si el proyecto es en idioma español —el equipo trabaja en español, los documentos están en español, el output final es en español— cambiar al inglés para ahorrar tokens introduce fricciones reales: más posibilidad de errores de traducción, contexto que se pierde, revisiones extra. Ese coste operativo puede superar perfectamente el ahorro en tokens.
El language tax es un coste relevante principalmente cuando el volumen de uso es muy alto y el inglés es viable como lengua de trabajo. Para la mayoría de equipos hoteleros en España, no lo es. Lo que vale la pena es conocer ese coste antes de decidir, no necesariamente cambiarse al inglés. La conclusión práctica no es “escríbele en inglés”, sino “elige el proveedor y el modelo con criterio, sabiendo lo que te cuesta cada uno en tu idioma”.

¿Qué significa todo esto para el sector hotelero y por qué es clave?
Los equipos de revenue y marketing llevan años siendo los early adopters de la tecnología en el hotel. Los revenue fueron los primeros en integrar RMS, los primeros en conectar PMS con herramientas de pricing dinámico, y ahora son de los primeros en incorporar flujos de trabajo con IA generativa. Mientras que los departamentos de marketing y ecommerce fueron los primeros en llevar las redes sociales a la estrategia del hotel, la creación y gestión de webs con CMS, los primeros en trabajar con herramientas de automatización de campañas y segmentación de audiencias, y ahora lideran la personalización de la experiencia digital del huésped antes incluso de que llegue a recepción.
Pero en esta adopción hay una variable que raramente se analiza: el idioma en el que se le habla a la máquina. Un revenue manager en España que cada mañana le pide a Claude que interprete el informe de demanda, que le proponga ajustes de tarifa, que redacte una respuesta a una review negativa en Booking y que genere un resumen ejecutivo para el comité de dirección… está consumiendo tokens a un ritmo muy superior al de su homólogo anglófono que hace exactamente lo mismo. Y esto tiene un coste que, en caso de ser muy elevado, podría limitar el uso de la herramienta debido al incremento inesperado de presupuesto.
Escenario concreto: imagina un equipo de revenue que realiza 50 interacciones diarias con una IA. Si cada interacción en español consume de media 300 tokens más que en inglés, estamos hablando de 15.000 tokens extra al día. En un mes, 450.000 tokens adicionales. En un año, más de 5 millones de tokens que no existirían si el mismo trabajo se hiciera en inglés. A las tarifas actuales de los principales proveedores, ese volumen puede representar centenares o incluso miles de euros anuales. Un coste que no aparece en ningún informe de P&L, pero que existe y que puede ser difícil de justificar ante una directiva no amigable con las últimas tecnologías del mercado.
Las buenas noticias
El gap se está reduciendo, y los modelos de nueva generación muestran mejoras claras en eficiencia multilingüe, y algunos proveedores han hecho de la paridad lingüística una prioridad técnica explícita. Además, hay estrategias prácticas para minimizar el impacto hoy mismo: escribir los prompts en inglés cuando el output final también puede serlo, usar plantillas bilingües para las interacciones más recurrentes, evaluar qué proveedor ofrece el mejor ratio para el idioma en el que trabaja tu equipo, y sobre todo, medir. Muy pocos equipos tienen visibilidad real del consumo de tokens por tarea. Tenerla es el primer paso para optimizarlo.
En Revenue Management estamos acostumbrados a optimizar cada variable: tarifa, canal, segmento, timing. Pero raramente miramos el coste de las herramientas con el mismo nivel de detalle con el que miramos el coste de adquisición de un cliente. El language tax es un recordatorio de que la IA no es neutral, y cada decisión de implementación —qué modelo, en qué idioma, para qué tarea— tiene un coste asociado. Y conocerlo es parte del trabajo, porque en revenue, cada euro cuenta, incluidos los que se van en tokens.